一致性哈希算法以及Go实现
什么是一致性哈希
一致哈希 是一种特殊的哈希算法。在使用一致哈希算法后,哈希表槽位数(大小)的改变平均只需要对 K/n 个关键字重新映射,其中 K 是关键字的数量,n是槽位数量。然而在传统的哈希表中,添加或删除一个槽位的几乎需要对所有关键字进行重新映射。
以上为维基百科中的介绍,很显然要想明白一致性哈希首先我们要先搞懂传统哈希
传统哈希用例
首先我们以一种简单的分布式缓存架构来阐述
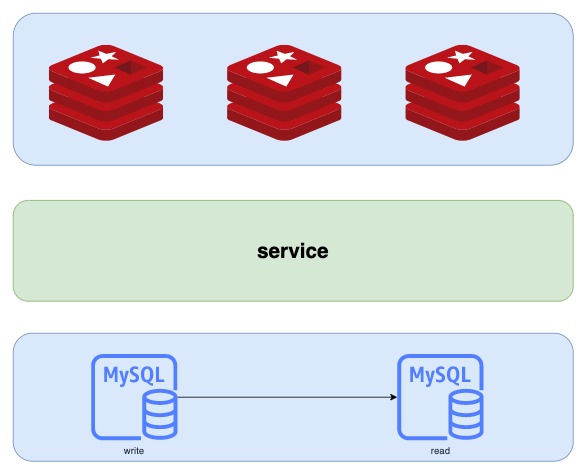
如图-1所示,我们有的时候后会使用redis对热点数据缓存进而缓解数据库的压力,理论上我们认为mysql的操作是高昂的。
这里多个redis本质上是多个集群
这个时候我们希望将热点数据均匀的打散到多个redis上,来降低单个redis集群为缓存造成节点访问过热的情况发生。简单的我们可以理解为将不同的数据转换唯一值后,按照redis数量取模。假设有3台redis做缓存。计算公式如下:
1 | |
我们把这3个redis对应编号,h的值就是这个数据应该落在的缓存redis的位置。这就是传统的hash使用的一种,类似的在数据库分表对数据操作的时候也可以使用这种方式。
传统哈希存在什么问题?
很明显存在这种问题:当我们其中一个redis断电之或者新增一个那么对应的全部缓存对应的要全部改变位置,因为节点的数量发生改变了,仍然用之前的计算方法数据落点全部出错。为了解决这个问题一致性哈希就出现了。
一致性哈希原理
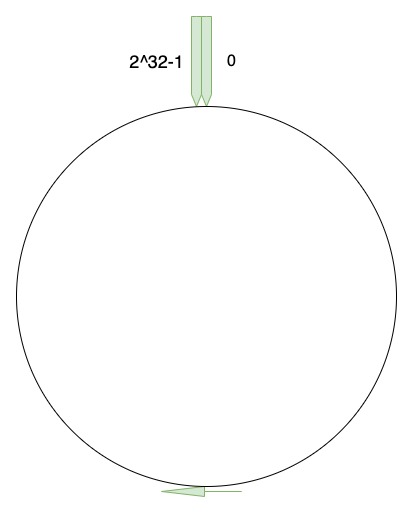
一致性哈希将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数 H 的值空间为 0-2^32-1(即哈希值是一个 32 位无符号整形),整个哈希空间环如下:
接下来就是将我们的缓存对象哈希化放到这个环中,访问数据的时候数据key也是用同样的算法计算出哈希,通过环上顺时针转动知道遇到第一个存贮节点,这个存储节点就是数据的保存节点。如图-3所
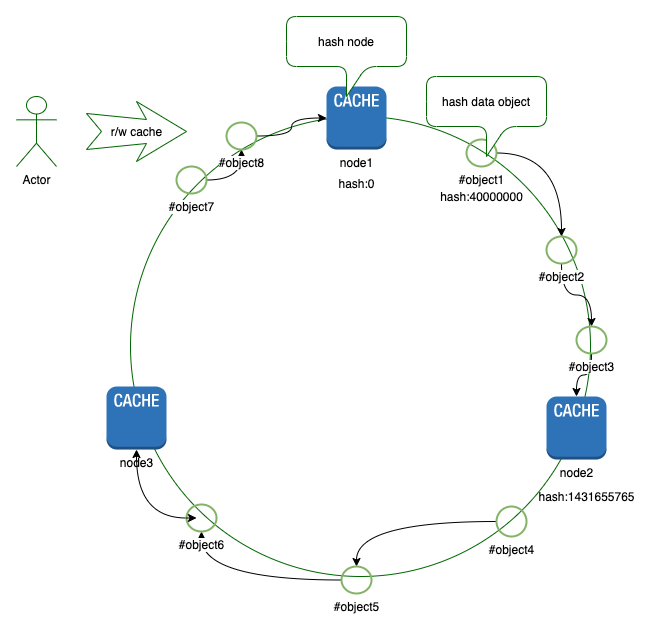
图-3中object1的key哈希之后为400000000顺时针转动知道遇到第一个存储对象node2所以object1保存的对象为node2。
一般的如果一个节点不可用则这个节点上的数据就会分配到相邻的节点上而其他key所在的位置不会变化。新增一个节点同理
一致性哈希引入虚拟节点解决分配不均问题
想必大聪明的你已经看出来了。当存储节点较少或者节点分配本身就不均衡的情况下,一些key落入的数据节点必然会不均衡,这个时候又会造成节点过热。为解决这个问题引入了虚拟节点。即一个真实节点对应了多个虚拟的节点如图-4所示:
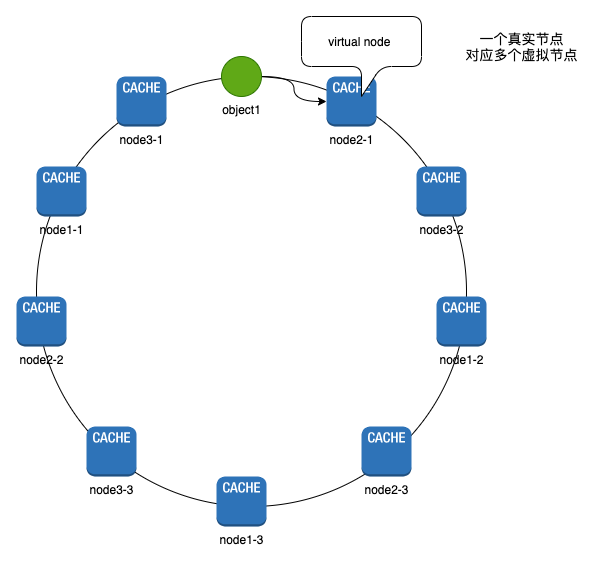
图-4中的虚拟节点并不是真实的存储节点,而是按照一定规则批量生成的虚拟节点。这些虚拟节点都有一个对应的真实节点。
一致性哈希与其哈希算法对比
对于集群中缓存类数据key的节点分配问题,有这几种解决方法,简单的hash取模,槽映射,一致性hash。
hash取模
对于hash取模,均衡性没有什么问题,但是如果集群中新增一个节点时,将会有N/(N+1)的数据实效,当N值越大,失效率越高。这显然是不可接受的。槽映射
redis采用的就是这种算法, 其思想是将key值做一定运算(如crc16, crc32,hash), 获得一个整数值,再将该值与固定的槽数取模(slots), 每个节点处理固定的slots。获取key所在的节点时,先要计算出key与槽的对应关系,再通过槽与节点的对应关系找到节点,这里每次新增节点时,只需要迁移一定槽对应的key即可,而不迁移的槽点key值则不会实效,这种方式将失效率降低到了 1/(N+1)。不过这种方式有个缺点就是所有节点都需要知道槽与节点对应关系,如果client端不保存槽与节点的对应关系的话,它需要实现重定向的逻辑。一致性hash
一致性hash如上文所言,其新增一个节点的失效率仅为1/(N+1),通过一致性hash最大程度的降低了实效率。同时相比于槽映射的方式,不需要引人槽来做中间对应,最大限度的简化了实现。
Go实现一致性哈希
代码实现详细github.com/dogslee/consistent
使用样例:
1 | |
Refrence
一致性哈希算法
5分钟理解一致性哈希算法
维基百科-一致性哈希
golang 实现一致性 hash 算法
一致性hash算法原理及golang实现
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!